SNS 크롤링 모듈 구현(instagram,facebook,twitter)
개요
💡 SNS 크롤링
OSINT 프로젝트를 하면서 공부한 내용으로 인터넷상의 돌아다니는 정보를 쉽게 수집하여 보여주는 프로젝트인 만큼 SNS의 정보를 가져와주는 모듈을 제작해봤다
언어는 PYTHON이며 selenium.webdriver를 이용하여 크롤링 했다
대표적인 sns인 instagram , facebook, twitter 크롤링을 목표로 했다.
전체 코드
# -*- coding: utf-8 -*-
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
import time, re
class SNSCrawler:
def __init__(self, driver_path):
self.driver_path = driver_path
def login_facebook(self, driver, target_url):
fb_url = 'https://mobile.facebook.com/'
login_name = ''
login_pw = ''
driver.implicitly_wait(10)
driver.get(fb_url)
time.sleep(3)
username_input = driver.find_element(By.CSS_SELECTOR, "input[name='email']")
password_input = driver.find_element(By.CSS_SELECTOR, "input[name='pass']")
username_input.send_keys(login_name)
password_input.send_keys(login_pw)
login_button = driver.find_element(By.XPATH , "//button[@type='button']")
login_button.click()
print('페이스북 로그인')
time.sleep(3)
driver.get(target_url)
time.sleep(3)
print('페이스북 진입성공')
def get_facebook_profile(self, username):
try:
url = 'https://mobile.facebook.com/' + username
options = webdriver.ChromeOptions()
options.add_argument('headless')
options.add_argument('--disable-extensions')
options.add_argument('--disable-gpu')
options.add_argument('--no-sandbox')
options.add_argument('--lang=ko_KR.UTF-8')
driver = webdriver.Chrome(executable_path=self.driver_path, options=options)
driver.get(url)
time.sleep(5)
self.login_facebook(driver, url)
time.sleep(5)
try:
name = driver.find_element(By.CSS_SELECTOR,'#cover-name-root > h3')
name = name.text
except:
name = 'None'
try:
element_present = EC.presence_of_element_located((By.CSS_SELECTOR, '#bio > div'))
WebDriverWait(driver, 10).until(element_present)
about = driver.find_element(By.CSS_SELECTOR,'#bio > div')
about = about.text
# about = driver.find_element(By.CSS_SELECTOR,'#bio > div')
# about = about.text.encode('utf-8').decode('utf-8')
except:
about = 'None'
try:
about_data = self.get_facebook_about(driver, username)
except:
about_data = {'contact' : 'a', 'birth': 'b', 'career': 'b'}
try:
profile_data = {
'name': name,
'about': about,
'contact': about_data['contact'],
'birth': about_data['birth'],
'career':about_data['career'],
}
return profile_data
except:
return None
except:
return None
def get_facebook_about(self, driver, username):
try:
url = 'https://mobile.facebook.com/' + username + '/about'
options = webdriver.ChromeOptions()
options.add_argument('headless')
options.add_argument('--disable-extensions')
options.add_argument('--disable-gpu')
options.add_argument('--no-sandbox')
options.add_argument('--lang=ko_KR.UTF-8')
driver = webdriver.Chrome(executable_path=self.driver_path, options=options)
driver.get(url)
time.sleep(5)
self.login_facebook(driver, url)
time.sleep(5)
try:
element_present = EC.presence_of_element_located((By.CSS_SELECTOR, '#contact-info'))
WebDriverWait(driver, 10).until(element_present)
contact = driver.find_element(By.CSS_SELECTOR,'#contact-info')
contact = contact.text
except:
contact = '1'
try:
element_present = EC.presence_of_element_located((By.CSS_SELECTOR, '#basic-info > div > div:nth-of-type(1) > div > div._5cdv.r'))
WebDriverWait(driver, 10).until(element_present)
birth = driver.find_element(By.CSS_SELECTOR,'#basic-info > div > div:nth-of-type(1) > div > div._5cdv.r')
birth = birth.text
except:
birth = '2'
try:
element_present = EC.presence_of_element_located((By.CSS_SELECTOR, '#work > div > div > div > div'))
WebDriverWait(driver, 10).until(element_present)
career = driver.find_element(By.CSS_SELECTOR,'#work > div > div > div > div')
career = career.text
except:
career = '3'
try:
about_data = {
'contact': contact,
'birth': birth,
'career': career,
}
filename = url[url.find('//')+3:]
filename = filename.replace('/','_')
f = open(filename+'.html','w', encoding='utf-8')
f.write(str(driver.page_source))
f.close()
#print(driver.page_source)
return about_data
except:
return None
except:
return None
def get_twitter_profile(self, username):
try:
url = 'https://twitter.com/' + username
options = webdriver.ChromeOptions()
options.add_argument('headless')
options.add_argument('--disable-extensions')
options.add_argument('--disable-gpu')
options.add_argument('--no-sandbox')
options.add_argument('--lang=ko_KR.UTF-8')
driver = webdriver.Chrome(executable_path=self.driver_path, options=options)
driver.get(url)
time.sleep(5)
try:
name = driver.find_element(By.CSS_SELECTOR , '#react-root > div > div > div.css-1dbjc4n.r-18u37iz.r-13qz1uu.r-417010 > main > div > div > div > div > div > div.css-1dbjc4n.r-aqfbo4.r-gtdqiz.r-1gn8etr.r-1g40b8q > div:nth-child(1) > div > div > div > div > div > div.css-1dbjc4n.r-16y2uox.r-1wbh5a2.r-1pi2tsx.r-1777fci > div > h2 > div > div > div > div > span.css-901oao.css-16my406.r-1awozwy.r-18jsvk2.r-6koalj.r-poiln3.r-b88u0q.r-bcqeeo.r-1udh08x.r-3s2u2q.r-qvutc0 > span > span:nth-child(1)')
name = name.text
except:
name = None
try:
screen_name = driver.find_element(By.CSS_SELECTOR , '#react-root > div > div > div.css-1dbjc4n.r-18u37iz.r-13qz1uu.r-417010 > main > div > div > div > div > div > div:nth-child(3) > div > div > div > div.css-1dbjc4n.r-1ifxtd0.r-ymttw5.r-ttdzmv > div.css-1dbjc4n.r-6gpygo.r-14gqq1x > div.css-1dbjc4n.r-1wbh5a2.r-dnmrzs.r-1ny4l3l > div > div.css-1dbjc4n.r-1awozwy.r-18u37iz.r-1wbh5a2 > div > div > div > span')
screen_name = screen_name.text
except:
screen_name = 'None'
try:
bio = driver.find_element(By.CSS_SELECTOR , '#react-root > div > div > div.css-1dbjc4n.r-18u37iz.r-13qz1uu.r-417010 > main > div > div > div > div > div > div:nth-child(3) > div > div > div > div.css-1dbjc4n.r-1ifxtd0.r-ymttw5.r-ttdzmv > div:nth-child(3) > div > div > span')
bio = bio.text
except:
bio = None
try:
location = driver.find_element(By.CSS_SELECTOR , '#react-root > div > div > div.css-1dbjc4n.r-18u37iz.r-13qz1uu.r-417010 > main > div > div > div > div > div > div:nth-child(3) > div > div > div > div.css-1dbjc4n.r-1ifxtd0.r-ymttw5.r-ttdzmv > div:nth-child(4) > div > span:nth-child(1) > span > span')
location = location.text
except:
location = None
try:
profile_img = driver.find_element(By.CSS_SELECTOR , '#react-root > div > div > div.css-1dbjc4n.r-18u37iz.r-13qz1uu.r-417010 > main > div > div > div > div > div > div:nth-child(3) > div > div > div > div.css-1dbjc4n.r-1ifxtd0.r-ymttw5.r-ttdzmv > div.css-1dbjc4n.r-1habvwh.r-18u37iz.r-1w6e6rj.r-1wtj0ep > div.css-1dbjc4n.r-1adg3ll.r-16l9doz.r-6gpygo.r-2o1y69.r-1v6e3re.r-bztko3.r-1xce0ei > div.r-1p0dtai.r-1pi2tsx.r-1d2f490.r-u8s1d.r-ipm5af.r-13qz1uu > div > div.r-1p0dtai.r-1pi2tsx.r-1d2f490.r-u8s1d.r-ipm5af.r-13qz1uu > div > a > div.css-1dbjc4n.r-14lw9ot.r-sdzlij.r-1wyvozj.r-1udh08x.r-633pao.r-u8s1d.r-1v2oles.r-desppf > div > div.r-1p0dtai.r-1pi2tsx.r-1d2f490.r-u8s1d.r-ipm5af.r-13qz1uu > div > img')
profile_img = profile_img.get_attribute('src')
except:
url = None
try:
joined_date = driver.find_element(By.CSS_SELECTOR , '#react-root > div > div > div.css-1dbjc4n.r-18u37iz.r-13qz1uu.r-417010 > main > div > div > div > div > div > div:nth-child(3) > div > div > div > div.css-1dbjc4n.r-1ifxtd0.r-ymttw5.r-ttdzmv > div:nth-child(4) > div > span.css-901oao.css-16my406.r-14j79pv.r-4qtqp9.r-poiln3.r-1b7u577.r-bcqeeo.r-qvutc0 > span')
joined_date = joined_date.text
except:
joined_date = None
try:
profile_data = {
'sns' : 'twitter',
'name': name,
'screen_name': screen_name,
'bio': bio,
'location': location,
'profile_img': profile_img,
'joined_date': joined_date
}
return profile_data
except:
return None
except:
return None
def login_instargram(self, driver, target_url, login_name, login_pw):
insta_url = 'https://www.instagram.com'
driver.implicitly_wait(10)
driver.get(insta_url)
time.sleep(3)
username_input = driver.find_element(By.CSS_SELECTOR, "input[name='username']")
password_input = driver.find_element(By.CSS_SELECTOR, "input[name='password']")
username_input.send_keys(login_name)
password_input.send_keys(login_pw)
login_button = driver.find_element(By.XPATH , "//button[@type='submit']")
login_button.click()
print('인스타그램 로그인')
time.sleep(3)
driver.get(target_url)
time.sleep(3)
print('인스타그램 진입성공')
def get_instagram_profile(self, username):
login_name = ''
login_pw = ''
try:
url = 'https://www.instagram.com/' + username
options = webdriver.ChromeOptions()
options.add_argument('headless')
options.add_argument('--disable-extensions')
options.add_argument('--disable-gpu')
options.add_argument('--no-sandbox')
options.add_argument('--lang=ko_KR.UTF-8')
driver = webdriver.Chrome(executable_path=self.driver_path, options=options)
driver.get(url)
time.sleep(5)
self.login_instargram(driver, url, login_name, login_pw)
time.sleep(5)
filename = url[url.find('//')+2:]
filename = filename.replace('/','_')
f = open(filename+'.html','w', encoding='utf-8')
f.write(str(driver.page_source))
f.close()
try:
bio_text = re.findall(r'mount_0_0_[a-zA-Z0-9_\-]{2}', str(driver.page_source))
bio_text = bio_text[0]
except:
print('bio_text error')
try:
name = driver.find_element(By.TAG_NAME, 'title').get_attribute('textContent')
name = name.split('•')[0]
except:
name = 'name'
try:
bio = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, f"#{bio_text} > div > div > div.x9f619.x1n2onr6.x1ja2u2z > div > div > div > div.x78zum5.xdt5ytf.x10cihs4.x1t2pt76.x1n2onr6.x1ja2u2z > div.x9f619.xnz67gz.x78zum5.x168nmei.x13lgxp2.x5pf9jr.xo71vjh.x1uhb9sk.x1plvlek.xryxfnj.x1c4vz4f.x2lah0s.x1q0g3np.xqjyukv.x1qjc9v5.x1oa3qoh.x1qughib > div.xh8yej3.x1gryazu.x10o80wk.x14k21rp.x1porb0y.x17snn68.x6osk4m > section > main > div > header > section > div._aa_c")))
bio = bio.text
except:
bio = bio_text
try:
post = driver.find_element(By.CSS_SELECTOR, 'meta[name="description"]')
post = post.get_attribute('content').split('-')[0]
# post = post.text
except:
post = None
try:
profile_img = driver.find_element(By.CSS_SELECTOR, 'meta[property="og:image"]')
profile_img = profile_img.get_attribute('content')
except:
profile_img = None
try:
profile_data = {
'sns' : 'instgram',
'name': name,
'bio': bio,
'post': post,
'profile_img': profile_img,
}
return profile_data
except Exception as e:
return e
except:
return '123'
if __name__ == '__main__':
scraper = SNSCrawler('D:\chromedriver_win32\chromedriver.exe')
instagram_profile = scraper.get_instagram_profile('joongsint')
#print(instagram_profile)
facebook_profile = scraper.get_facebook_profile('joongsint')
#print(facebook_profile)
twitter_profile = scraper.get_twitter_profile('joongsint')
print(facebook_profile)
print(instagram_profile)
print(twitter_profile)출력모습
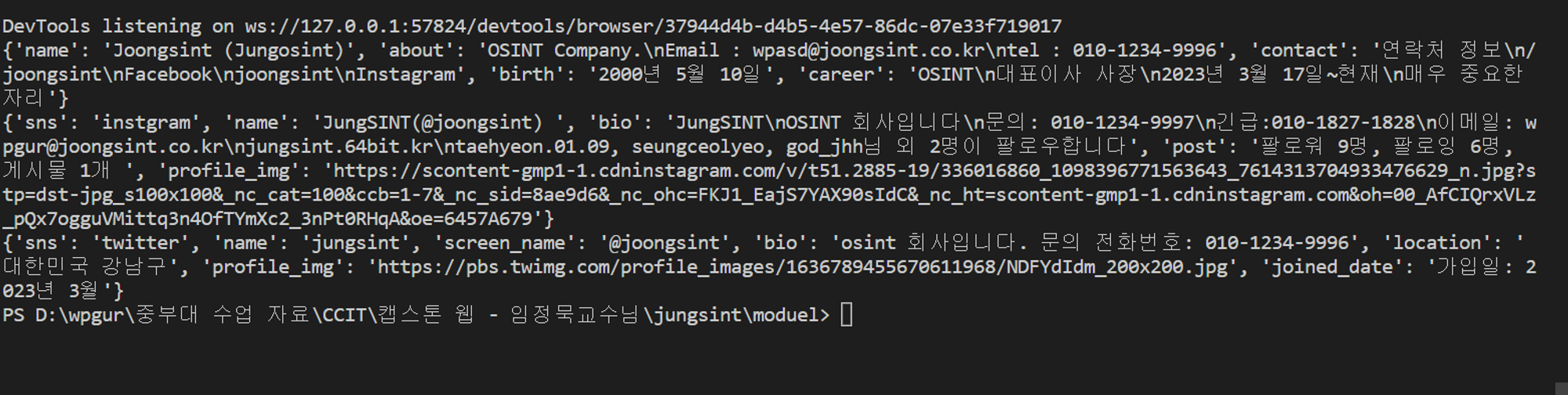
공통 적용
- 시작 부분
파이썬이 실행되면 제일 먼저 실행되는 부분이다.
selenium.webdriver를 사용하기 위해서는 chromedriver.exe를 다운받아 사용해야하며 이는 인터넷에서 다운 받아야한다.
코드를 살펴보면 아래에 나오는 클래스에 chromedriver.exe경로를 인자로 넘겨줘서 선언해주고
instagram_profile 함수에 검색하고자 하는 사용자를 인자로 넘겨준다.
if __name__ == '__main__':
scraper = SNSCrawler('D:\chromedriver_win32\chromedriver.exe')
instagram_profile = scraper.get_instagram_profile('joongsint')
#print(instagram_profile)
facebook_profile = scraper.get_facebook_profile('joongsint')
#print(facebook_profile)
twitter_profile = scraper.get_twitter_profile('joongsint')
print(facebook_profile)
print(instagram_profile)
print(twitter_profile)- 클래스화
총 3가지의 sns를 다루기에 편하게 관리하기 위해 클래스로 제작했다.
다음은 클래스가 처음만들어지게 되면 공통으로 사용할 수 있는 driver의 경로이다.
다른 곳에서 사용될때 self.driver_path 변수를 사용할 수 있으며 모든 함수의 첫번째 인자는 self가 되어야한다.
class SNSCrawler:
def __init__(self, driver_path):
self.driver_path = driver_path
instagram 크롤링
- 시작 부분
인스타 그램은 로그인 이 되어야 원할한 프로필 검색이 가능하다 따라서 로그인 할수있는 정보를 입력해줘야하고 크롤링을 위한 driver의 옵션들을 설정해준다.
이후 로그인해주는 함수를 실행해 주는데 이때 self를 앞에 붙여줘야 class안에 있는 함수로 제대로 인식한다.
추가로 sleep을 해주는 이유는 크롤링할때 계정이 차단당하지 않기위한 장치이다.
def get_instagram_profile(self, username):
login_name = ''
login_pw = ''
try:
url = 'https://www.instagram.com/' + username
options = webdriver.ChromeOptions()
options.add_argument('headless')
options.add_argument('--disable-extensions')
options.add_argument('--disable-gpu')
options.add_argument('--no-sandbox')
options.add_argument('--lang=ko_KR.UTF-8')
driver = webdriver.Chrome(executable_path=self.driver_path, options=options)
driver.get(url)
time.sleep(5)
self.login_instargram(driver, url, login_name, login_pw)
time.sleep(5)- 인스타 로그인 함수
인스타 로그인 함수에서는 원래 url로 돌아가기위한 url을 인자로 받고 각 아이디와 비밀번호를 인자로 받는다.
함수가 실행 되면 id 와 pw가 입력 되는 위치를 By.CSS_SELECTOR 로 찾아 준뒤 값을 .send_keys 로 넣어 주고 로그인 페이지의 submit 타입의 버튼은 로그인 버튼 하나기에 버튼을 찾아 click해줘서 로그인 을 진행한다
이후 로그인을 하기 위해 잠시 driver의 url을 'https://www.instagram.com' 로 바꿔준걸 다시 크롤링 하기위한 target_url 로 바꿔준다.
def login_instargram(self, driver, target_url, login_name, login_pw):
insta_url = 'https://www.instagram.com'
driver.implicitly_wait(10)
driver.get(insta_url)
time.sleep(3)
username_input = driver.find_element(By.CSS_SELECTOR, "input[name='username']")
password_input = driver.find_element(By.CSS_SELECTOR, "input[name='password']")
username_input.send_keys(login_name)
password_input.send_keys(login_pw)
login_button = driver.find_element(By.XPATH , "//button[@type='submit']")
login_button.click()
print('인스타그램 로그인')
time.sleep(3)
driver.get(target_url)
time.sleep(3)
print('인스타그램 진입성공')- 파일 저장
다시 get_instagram_profile 함수로 돌아가자면 url을 이용하여 instagram으로 file이름을 설정해주고 driver.page_source 의 변수는 모든 페이지 소스를 담고 있는데 이를 그대로 html 파일로 저장하게 만든다
이 기능은 디버깅을 하기 위한 코드로 제작했다.
filename = url[url.find('//')+2:]
filename = filename.replace('/','_')
f = open(filename+'.html','w', encoding='utf-8')
f.write(str(driver.page_source))
f.close()- 크롤링 제한 장치 우회
인스타 그램은 최상위 div의 id값을 랜덤으로 바꿔준다…. 원레 크롤링은 저 id값을 통해 크롤링을 해오는데 마지막 두글자를 계속 랜덤으로 바꿔서 아주 고생했다.
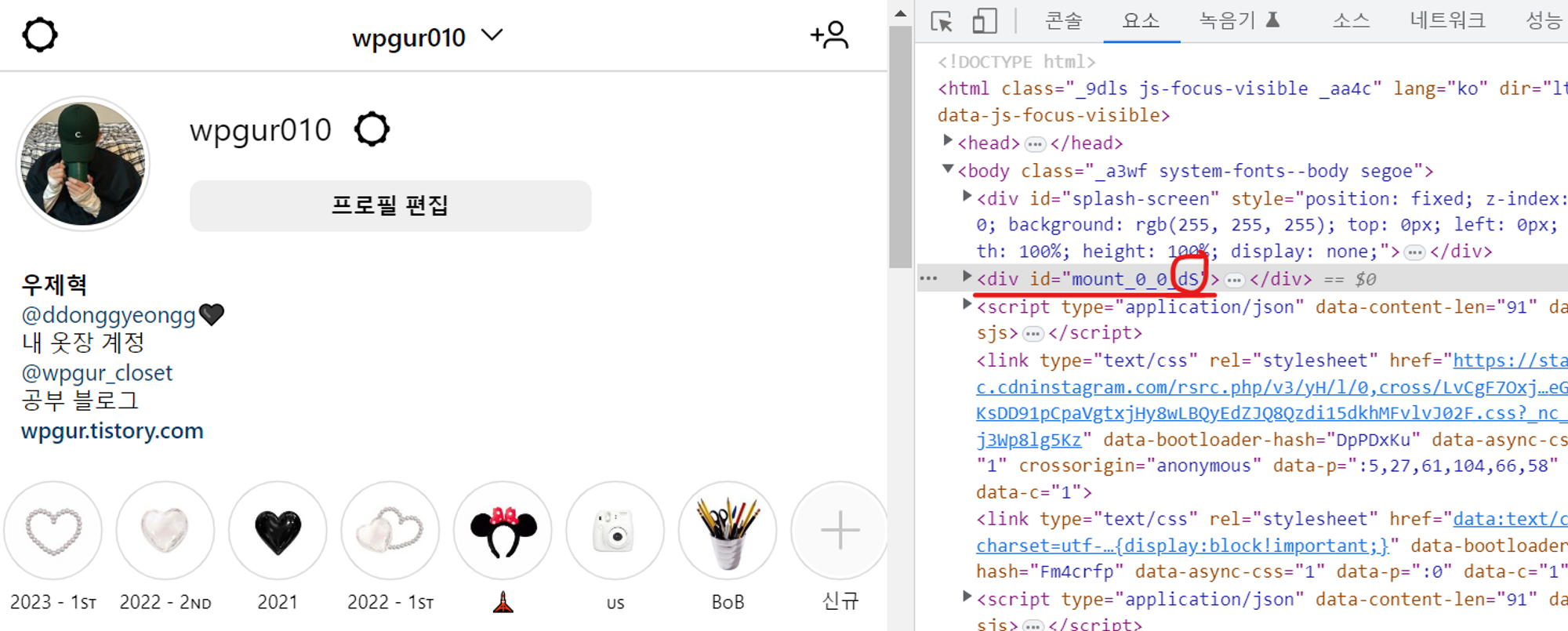
따라서 생각해 낸 방법은 정규표현식으로 마지막 글자 두글자를 매번 새롭게 가져오는 것이다
다음코드는 그에 관한 부분인데 mount_0_0_ 부분은 같으니 모든 코드를 가지고 있는 driver.page_source 변수를 사용해서 mount_0_0_ 뒤에 두글자를 함께 가져올수 있게 코드를 짜서 bio_text에 저장했다.
bio_text[0] 으로 한 이유는 javascript에도 mount_0_0_ 이 단어가 들어있어 2개가 저장되는데 그중 하나만 가져오려고 했다.
try:
bio_text = re.findall(r'mount_0_0_[a-zA-Z0-9_\-]{2}', str(driver.page_source))
bio_text = bio_text[0]
except:
print('bio_text error')- 본격적인 크롤링
최상위 div의 id값도 제대로 가져올수 있게 되어서 이제 맘편히 가져오고 싶은 부분을 css값으로 찾아 이름, 자기소개, 게시물 정보, 프로필 이미지의 url 총 4가지의 정보를 가져온다. bio(자기소개) 코드 부분을 보면 최상위 div의 id값(bio_text)을 이용하는 걸 볼 수 있다.
추가로 오류를 막기위해 모든 코드를 try로 묶었다.
try:
name = driver.find_element(By.TAG_NAME, 'title').get_attribute('textContent')
name = name.split('•')[0]
except:
name = 'name'
try:
bio = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, f"#{bio_text} > div > div > div.x9f619.x1n2onr6.x1ja2u2z > div > div > div > div.x78zum5.xdt5ytf.x10cihs4.x1t2pt76.x1n2onr6.x1ja2u2z > div.x9f619.xnz67gz.x78zum5.x168nmei.x13lgxp2.x5pf9jr.xo71vjh.x1uhb9sk.x1plvlek.xryxfnj.x1c4vz4f.x2lah0s.x1q0g3np.xqjyukv.x1qjc9v5.x1oa3qoh.x1qughib > div.xh8yej3.x1gryazu.x10o80wk.x14k21rp.x1porb0y.x17snn68.x6osk4m > section > main > div > header > section > div._aa_c")))
bio = bio.text
except:
bio = bio_text
try:
post = driver.find_element(By.CSS_SELECTOR, 'meta[name="description"]')
post = post.get_attribute('content').split('-')[0]
# post = post.text
except:
post = None
try:
profile_img = driver.find_element(By.CSS_SELECTOR, 'meta[property="og:image"]')
profile_img = profile_img.get_attribute('content')
except:
profile_img = None- instagram 마무리
그렇게 크롤링 한 내용들을 profile_data 리스트에 담아 return 해준다.
try:
profile_data = {
'sns' : 'instgram',
'name': name,
'bio': bio,
'post': post,
'profile_img': profile_img,
}facebook 크롤링
- 시작부분
인스타와 동일하게 프로필 url을 설정하고driver의 옵션을 설정하고 facebook도 로그인을 안하면 다른 사람의 정보 검색도 잘 안되기에 로그인 해줘야 한다.
def get_facebook_profile(self, username):
try:
url = 'https://mobile.facebook.com/' + username
options = webdriver.ChromeOptions()
options.add_argument('headless')
options.add_argument('--disable-extensions')
options.add_argument('--disable-gpu')
options.add_argument('--no-sandbox')
options.add_argument('--lang=ko_KR.UTF-8')
driver = webdriver.Chrome(executable_path=self.driver_path, options=options)
driver.get(url)
time.sleep(5)
self.login_facebook(driver, url)
time.sleep(5)- 이름과 자기소개 크롤링
무난하게 크롤링 위치의 css값을 가져와 뽑아낸다.
힘들었던 점이 자기소개의 한글이 뭔 짓을 해줘도 깨져서 오기에 스트레스 안받을라고 자기소개를 다 영어로 바꿔줬다
해결못함!
try:
name = driver.find_element(By.CSS_SELECTOR,'#cover-name-root > h3')
name = name.text
except:
name = 'None'
try:
element_present = EC.presence_of_element_located((By.CSS_SELECTOR, '#bio > div'))
WebDriverWait(driver, 10).until(element_present)
about = driver.find_element(By.CSS_SELECTOR,'#bio > div')
about = about.text
# about = driver.find_element(By.CSS_SELECTOR,'#bio > div')
# about = about.text.encode('utf-8').decode('utf-8')
except:
about = 'None'- about 페이지 크롤링
다른 sns와 다르게 facebook은 프로필이 검색되려면 따로 프로필검색설정도 해줘야하고 중요한 정보는 facebook/사용자이름/about 페이지에 들어 있어 따로 about 페이지에서의 정보도 가져오려고 함수를 만들었다.
try:
about_data = self.get_facebook_about(driver, username)
except:
about_data = {'contact' : 'a', 'birth': 'b', 'career': 'b'}거의 같은 방법으로 facebook about page로 들어가는데 주의해야할 점은 url이 바뀌기 때문에 로그인 함수를 다시 사용해줘야한다!!
이후 css값으로 잘 크롤링해주고 return 해준다.
def get_facebook_about(self, driver, username):
try:
url = 'https://mobile.facebook.com/' + username + '/about'
options = webdriver.ChromeOptions()
options.add_argument('headless')
options.add_argument('--disable-extensions')
options.add_argument('--disable-gpu')
options.add_argument('--no-sandbox')
options.add_argument('--lang=ko_KR.UTF-8')
driver = webdriver.Chrome(executable_path=self.driver_path, options=options)
driver.get(url)
time.sleep(5)
self.login_facebook(driver, url)
time.sleep(5)
try:
element_present = EC.presence_of_element_located((By.CSS_SELECTOR, '#contact-info'))
WebDriverWait(driver, 10).until(element_present)
contact = driver.find_element(By.CSS_SELECTOR,'#contact-info')
contact = contact.text
except:
contact = '1'
try:
element_present = EC.presence_of_element_located((By.CSS_SELECTOR, '#basic-info > div > div:nth-of-type(1) > div > div._5cdv.r'))
WebDriverWait(driver, 10).until(element_present)
birth = driver.find_element(By.CSS_SELECTOR,'#basic-info > div > div:nth-of-type(1) > div > div._5cdv.r')
birth = birth.text
except:
birth = '2'
try:
element_present = EC.presence_of_element_located((By.CSS_SELECTOR, '#work > div > div > div > div'))
WebDriverWait(driver, 10).until(element_present)
career = driver.find_element(By.CSS_SELECTOR,'#work > div > div > div > div')
career = career.text
except:
career = '3'
try:
about_data = {
'contact': contact,
'birth': birth,
'career': career,
}
filename = url[url.find('//')+3:]
filename = filename.replace('/','_')
f = open(filename+'.html','w', encoding='utf-8')
f.write(str(driver.page_source))
f.close()
#print(driver.page_source)
return about_data
except:
return None
except:
return None- facebook 마무리
총 5가지 정보인 이름 , 자기소개, 연락처(전화번호 or sns계정), 생일, 직장 을 가져온다.
try:
profile_data = {
'name': name,
'about': about,
'contact': about_data['contact'],
'birth': about_data['birth'],
'career':about_data['career'],
}
return profile_datatwitter 크롤링
비교적 너어어무 편했다 따로 로그인할 필요도 없고 그냥 프로필 페이지에 정보들이 다 들어가 있어서 아주 편하게 크롤링 했다
instagram과 facebook의 크롤링 부분과 비슷하다.
def get_twitter_profile(self, username):
try:
url = 'https://twitter.com/' + username
options = webdriver.ChromeOptions()
options.add_argument('headless')
options.add_argument('--disable-extensions')
options.add_argument('--disable-gpu')
options.add_argument('--no-sandbox')
options.add_argument('--lang=ko_KR.UTF-8')
driver = webdriver.Chrome(executable_path=self.driver_path, options=options)
driver.get(url)
time.sleep(5)
try:
name = driver.find_element(By.CSS_SELECTOR , '#react-root > div > div > div.css-1dbjc4n.r-18u37iz.r-13qz1uu.r-417010 > main > div > div > div > div > div > div.css-1dbjc4n.r-aqfbo4.r-gtdqiz.r-1gn8etr.r-1g40b8q > div:nth-child(1) > div > div > div > div > div > div.css-1dbjc4n.r-16y2uox.r-1wbh5a2.r-1pi2tsx.r-1777fci > div > h2 > div > div > div > div > span.css-901oao.css-16my406.r-1awozwy.r-18jsvk2.r-6koalj.r-poiln3.r-b88u0q.r-bcqeeo.r-1udh08x.r-3s2u2q.r-qvutc0 > span > span:nth-child(1)')
name = name.text
except:
name = None
try:
screen_name = driver.find_element(By.CSS_SELECTOR , '#react-root > div > div > div.css-1dbjc4n.r-18u37iz.r-13qz1uu.r-417010 > main > div > div > div > div > div > div:nth-child(3) > div > div > div > div.css-1dbjc4n.r-1ifxtd0.r-ymttw5.r-ttdzmv > div.css-1dbjc4n.r-6gpygo.r-14gqq1x > div.css-1dbjc4n.r-1wbh5a2.r-dnmrzs.r-1ny4l3l > div > div.css-1dbjc4n.r-1awozwy.r-18u37iz.r-1wbh5a2 > div > div > div > span')
screen_name = screen_name.text
except:
screen_name = 'None'
try:
bio = driver.find_element(By.CSS_SELECTOR , '#react-root > div > div > div.css-1dbjc4n.r-18u37iz.r-13qz1uu.r-417010 > main > div > div > div > div > div > div:nth-child(3) > div > div > div > div.css-1dbjc4n.r-1ifxtd0.r-ymttw5.r-ttdzmv > div:nth-child(3) > div > div > span')
bio = bio.text
except:
bio = None
try:
location = driver.find_element(By.CSS_SELECTOR , '#react-root > div > div > div.css-1dbjc4n.r-18u37iz.r-13qz1uu.r-417010 > main > div > div > div > div > div > div:nth-child(3) > div > div > div > div.css-1dbjc4n.r-1ifxtd0.r-ymttw5.r-ttdzmv > div:nth-child(4) > div > span:nth-child(1) > span > span')
location = location.text
except:
location = None
try:
profile_img = driver.find_element(By.CSS_SELECTOR , '#react-root > div > div > div.css-1dbjc4n.r-18u37iz.r-13qz1uu.r-417010 > main > div > div > div > div > div > div:nth-child(3) > div > div > div > div.css-1dbjc4n.r-1ifxtd0.r-ymttw5.r-ttdzmv > div.css-1dbjc4n.r-1habvwh.r-18u37iz.r-1w6e6rj.r-1wtj0ep > div.css-1dbjc4n.r-1adg3ll.r-16l9doz.r-6gpygo.r-2o1y69.r-1v6e3re.r-bztko3.r-1xce0ei > div.r-1p0dtai.r-1pi2tsx.r-1d2f490.r-u8s1d.r-ipm5af.r-13qz1uu > div > div.r-1p0dtai.r-1pi2tsx.r-1d2f490.r-u8s1d.r-ipm5af.r-13qz1uu > div > a > div.css-1dbjc4n.r-14lw9ot.r-sdzlij.r-1wyvozj.r-1udh08x.r-633pao.r-u8s1d.r-1v2oles.r-desppf > div > div.r-1p0dtai.r-1pi2tsx.r-1d2f490.r-u8s1d.r-ipm5af.r-13qz1uu > div > img')
profile_img = profile_img.get_attribute('src')
except:
url = None
try:
joined_date = driver.find_element(By.CSS_SELECTOR , '#react-root > div > div > div.css-1dbjc4n.r-18u37iz.r-13qz1uu.r-417010 > main > div > div > div > div > div > div:nth-child(3) > div > div > div > div.css-1dbjc4n.r-1ifxtd0.r-ymttw5.r-ttdzmv > div:nth-child(4) > div > span.css-901oao.css-16my406.r-14j79pv.r-4qtqp9.r-poiln3.r-1b7u577.r-bcqeeo.r-qvutc0 > span')
joined_date = joined_date.text
except:
joined_date = None
try:
profile_data = {
'sns' : 'twitter',
'name': name,
'screen_name': screen_name,
'bio': bio,
'location': location,
'profile_img': profile_img,
'joined_date': joined_date
}
return profile_data
except:
return None
except:
return None